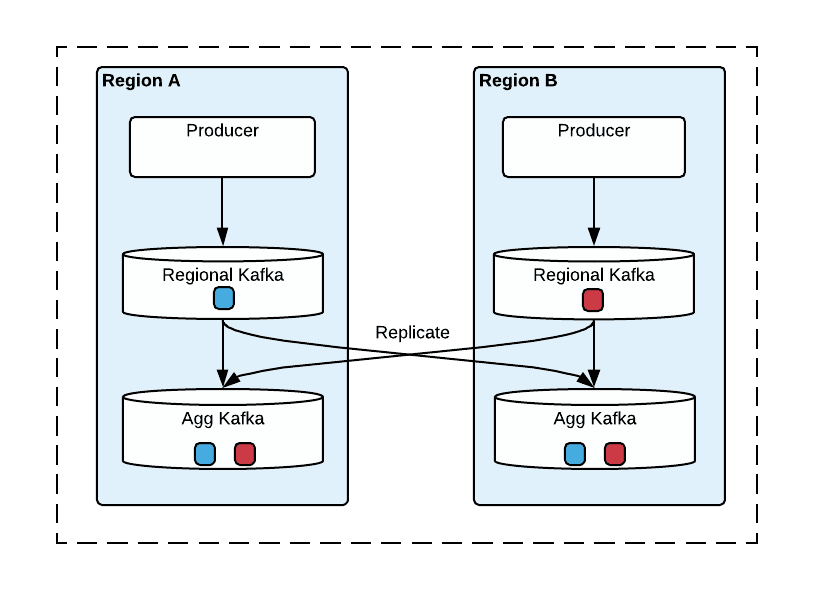
Stream producers only write to a stream in their own region.
There is another stream - “aggregate stream/cluster” - which is replicated across all the regions. (In other words, data is duplicated in every region.) Data from the region-level streams is moved into this one.
Consumers need to be more complex if they want to support failovers. They work in 2 ways:
Active-active.
Each region has an active consumer that runs redundant business logic.
If the system overall needs to create one view of data - for e.g., the blog suggests one database, across all regions, that contains surge pricing data - it needs a coordinator that tells all the region-level consumers which region contains the database they need to write to. If the region has issues, it coordinates the failover to another region.
I found a couple of things weird in the article.
Why did they create a single database for surge pricing? If the stream data was anyway replicated across all the regions, they could’ve created a region-level database and have the database clients pick the region closest to them.
It says the Flink job is resource-intensive. So, isn’t it expensive to duplicate that job across all their regions?
Active-passive:
There is one active consumer in one region. However, how do you support failover to another region?
They replicate checkpoints across the regions. That way, a new consumer can restart from the last known checkpoint.
One caveat is around offsets. (I think this is same as stream-sequence-ids.)
These offsets can can be in different order in different regions of the aggregation stream (for e.g., writes from a regional stream of my region will come in faster than those from other regions).
So, they describe an algorithm to maintain offset mappings across regions so that a new consumer can pick the right offset during failover. (I didn’t read this algorithm in detail.)